SEO -> Bagaimana Cara Menganalisis Perayapan Googlebot untuk Masalah Infisiensi
2/18/2025 08:20:00 PM ・0 comments ・Topic: analisis googlebot perayapan SEO
Ketidakefisienan anggaran perayapan dapat memengaruhi kinerja penelusuran organik jika konten baru atau yang diperbarui tidak dirayapi dan diindeks.
Dalam “Apa Arti Anggaran Perayapan untuk Googlebot,” Google menjelaskan dalam Blog Pusat Webmaster bahwa ada dua faktor yang mengontrol anggaran perayapan: tingkat perayapan dan permintaan perayapan. “Dengan menggabungkan laju perayapan dan permintaan perayapan, kami menetapkan anggaran perayapan sebagai URL yang dapat dan ingin dirayapi Googlebot.”
Google menegaskan bahwa anggaran crawl tidak memengaruhi situs dengan kurang dari beberapa ribu halaman. Namun situs e-niaga sering kali memiliki lebih banyak halaman, sehingga berpotensi menimbulkan masalah.
Dalam posting ini, saya akan menjelaskan cara menghasilkan laporan untuk membantu menentukan apakah situs Anda memiliki masalah anggaran crawl Googlebot. Tujuannya adalah untuk membuat daftar halaman web baru atau yang diperbarui yang belum dirayapi (dan, karenanya, diindeks). Saya akan melakukan ini dengan membuat daftar semua URL di peta situs XML situs, dengan tanggal pembuatan atau modifikasi.
Kemudian, saya akan membandingkan daftar itu dengan aktivitas perayapan Googlebot di log server web. File log memberikan sumber informasi terbaik saat menganalisis anggaran crawl. Saya membahas masalah ini di "Menggunakan Log Server untuk Mengungkap Masalah SEO".
Saya akan menggunakan Penganalisis File Log Screaming Frog untuk memulai.
File Log
Pertama, masukkan file log Anda ke Penganalisis File Log di "Seret dan Lepas File Log di Sini". Ini akan membuka tab "Proyek", untuk mengkonfigurasi analisis baru.
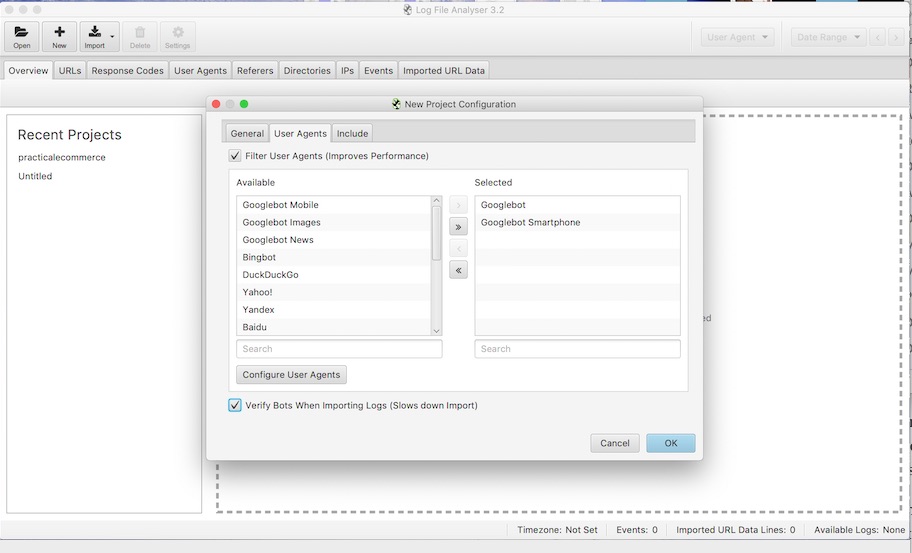
Screaming Frog's Log File Analyzer dapat muncul saat Googlebot merayapi laman.
Selanjutnya, potong file log untuk memisahkan entri Googlebot. Sebagian besar situs menerima perayapan dari, berpotensi, lusinan bot, seperti Googlebot, Bingbot, mesin telusur lain, dan alat SEO. Kami juga perlu menghapus permintaan Googlebot "palsu", yang umum dari alat yang meniru Google untuk, sebagian besar, analisis yang sah.
Untuk melakukan ini, di tab Proyek buka Baru> Agen Pengguna dan centang kotak "Verifikasi Bot Saat Mengimpor Log (Memperlambat Impor)." Tindakan ini memverifikasi IP Googlebot itu asli dengan melakukan verifikasi DNS ganda, seperti yang dijelaskan Google di "Memverifikasi Googlebot", di portal bantuan Search Console.
Menggunakan file log E-niaga Praktis sebagai contoh, menghilangkan perayapan Googlebot palsu mengurangi permintaan individu dari 306.960 menjadi 112.308 - kira-kira setengah dari permintaan Googlebot adalah palsu, dengan kata lain.
Selanjutnya, setelah Penganalisis File Log memproses log, saya akan mengekspornya menjadi file CSV yang terstruktur dan bersih. Saya akan memilih opsi "Status Verifikasi Tunjukkan Terverifikasi". Ini menghapus entri Googlebot palsu. Ketika saya membuat proyek dan memilih zona waktu kami, tanggal di log diformat dengan benar. Sekarang kita hanya perlu mengekspor file CSV.
Peta Situs XML
Saya akan menggunakan, sekali lagi, peta situs XML E-niaga Praktis sebagai contoh. Saya akan menganggapnya komprehensif dan hanya menyertakan URL unik yang ingin kami rayapi dan indeks. Saya juga akan berasumsi bahwa tanggal modifikasi terakhir di peta situs XML sudah akurat.
Peta situs XML memegang kunci untuk analisis anggaran perayapan kami:
- Apakah ada halaman atau pembaruan yang tidak di-crawl? Kami dapat menjawab ini dengan membandingkan halaman di peta situs XML dengan halaman yang dirayapi dari log.
- Seberapa cepat perubahan diambil? Kita dapat menjawabnya dengan membandingkan waktu modifikasi dengan waktu perayapan.
Pertama-tama saya harus mengonversi peta situs XML ke file CSV. Saya mencoba Screaming Frog's SEO Spider untuk mengunduh peta situs XML dan mengekspornya ke CSV, tetapi waktu modifikasi kritisnya berkurang.

Saya akan menggunakan Python sebagai gantinya.
Membandingkan URL di peta situs dengan file CSV. Pertama, saya akan memperluas peta situs indeks XML dan mengurai masing-masing peta situs menjadi Pandas DataFrame. ("Pandas" adalah pustaka perangkat lunak untuk Python untuk melakukan berbagai jenis analisis. "DataFrame" setara dengan Google Spreadsheet tetapi dengan kemampuan untuk melakukan transformasi data yang lebih kuat.) Berikut kodenya:
https://gist.github.com/hamletbatista/5d0d996872239ddbfe8744da049124a9.
Saya kemudian mengekspor DataFrame ke file CSV dan mengimpornya ke Penganalisis File Log. Ketika saya memilih tab URL, dan "Tidak di File Log" dari menu pulldown, saya mendapatkan jawaban untuk pertanyaan pertama: daftar URL yang belum dirayapi tetapi seharusnya.
Membandingkan waktu modifikasi dengan waktu perayapan. Untuk menjawab pertanyaan kedua - Seberapa cepat perubahan diambil? - kami perlu membandingkan tanggal modifikasi terakhir di peta situs dengan tanggal perayapan di file log. Sayangnya, Penganalisis File Log tidak menawarkan fitur ini.
Ini kembali ke Python.
Saya sudah memiliki peta situs XML di Pandas DataFrame. Sekarang saya akan memuat ekspor CSV dari Log File Analyzer ke DataFrame lain. Saya kemudian dapat menggabungkan dua DataFrames menggunakan fungsi gabungan Pandas.
Ada opsi untuk menggabungkan tergantung pada data yang ingin kita simpan. Dalam kasus ini, saya akan menggunakan "Left Join" untuk mempertahankan URL peta situs XML dan menangkap persimpangan antara peta situs dan file log. Berikut kode untuk melakukannya:
https://gist.github.com/hamletbatista/b8801049ae464398404a8f9bc755ad26
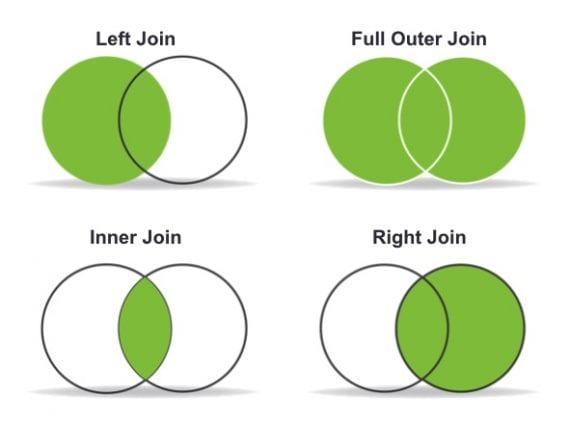
Gabungkan dua DataFrames menggunakan fungsi gabungan Pandas. Gunakan "Left Join" untuk menyimpan URL peta situs XML dan menangkap persimpangan antara peta situs dan file log.
Setelah kami menggabungkan DataFrames, kami dapat menentukan halaman mana yang tidak di-crawl (karena tanggal crawl hilang), menggunakan kode ini:
https://gist.github.com/hamletbatista/5e3a65bc19427d8c5570482b572d04b2.
Outputnya adalah daftar halaman yang belum di-crawl oleh Googlebot selama periode file log.
Pertanyaan paling menarik adalah apakah URL yang baru-baru ini diubah sedang dirayapi. Untuk ini, saya dapat membandingkan tanggal perayapan di file log dan tanggal modifikasi terakhir di peta situs XML:
https://gist.github.com/hamletbatista/02fb89d885825398c611cba57fbdb3ec.
Hasilnya adalah daftar halaman yang diperbarui yang telah di-crawl dengan cepat dan daftar lainnya yang tidak.
Sekarang kita dapat menentukan apakah E-niaga Praktis memiliki masalah anggaran perayapan. Kami dapat meninjau URL yang belum dirayapi, dan menyisipkan yang penting di alat "inspeksi URL" Search Console. Ini harus memberikan rincian mengapa. Kami juga dapat meminta pengindeksan ulang di fitur inspeksi.
Post a Comment
If you can't commemt, try using Chrome instead.